In an ideal world, scaling and merging would be fully automated and fool-proof. Perhaps
it is a consequence of using a combination of programs from different sources, but the
naive way of dealing with kappaCCD data will lead to either reflections being rejected
(by Scalepack) or to inclusion of overloaded (i.e. worse-than-useless)
data (by SADABS). While it would be possible to write a program to compare the
'fast' and 'slow' scan '.hkl' files, calculate scaling parameters etc. it is always
instructive to delve into the problem to ensure that no spurious data are included.
The process described here requires a bit of work to identify the outliers, but it
works.
We will use refinement diagnostics from an actual structure refinement run against the
'slow' data set to identify the problem reflections (in the slow-scan set). This
means that you need to solve your structure, clean it up (assign atom types etc.),
and run a few rounds of refinement with unmerged data (the model does not have to be
'finished', but it does have to be 'right'). This is just part of what you would do in
any case, even if you weren't trying to get an optimally merged dataset, so even though
it sounds like a lot of extra work, it really isn't.
In any case, once you are at a suitable state of refinement [with SHELXL using
MERG 0 in the '.ins'/'.res' files of course!], you need to open the last SHELXL
'.lst' file and scroll down to the list of "Most Disagreeable Reflections". In the
example here it looks like this:
5/6) KappaCCD: Find and Remove Overloads
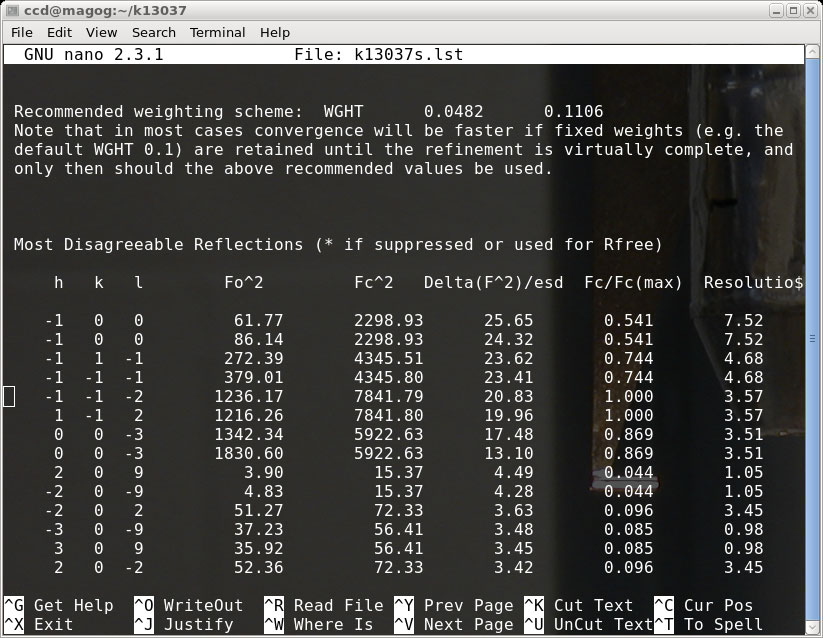
What to make of this ? The top eight reflections have Fo^2 << Fc^2. Notice also
that these are all at very or fairly low resolution (high numbers in the last column
equal low resolution - it's a reciprocal thing!). These eight are candidates for
being overloaded intensties. The (-1 0 0) data points could feasibly be partially
obscured by the beamstop, but even 7.52Å is not quite low enough resolution
for that on our kappaCCD. One might naively think that overloads would show up as
maxed out numbers, but that is not the case. Perhaps it has to do with how the
detector copes with too-high x-ray flux, coupled with how Denzo handles the
confusion. Who knows ? It matters not, because it is fixable.
We can use the 'fast' scan to check if these sets of indices show up as "disgreeable" when the model is refined against the 'fast' dataset. This is of course a valuable check, and will also tell us whether (-1 0 0) was hidden by the beamstop. In the present case there are no such "disagreeables" with the 'fast' set, and a quick check of the 'fast' '.hkl' file shows that there are reflections (or symmetry equivalents) available to fill the gaps when we eliminate these reflections from the 'slow' set.
We can use the 'fast' scan to check if these sets of indices show up as "disgreeable" when the model is refined against the 'fast' dataset. This is of course a valuable check, and will also tell us whether (-1 0 0) was hidden by the beamstop. In the present case there are no such "disagreeables" with the 'fast' set, and a quick check of the 'fast' '.hkl' file shows that there are reflections (or symmetry equivalents) available to fill the gaps when we eliminate these reflections from the 'slow' set.
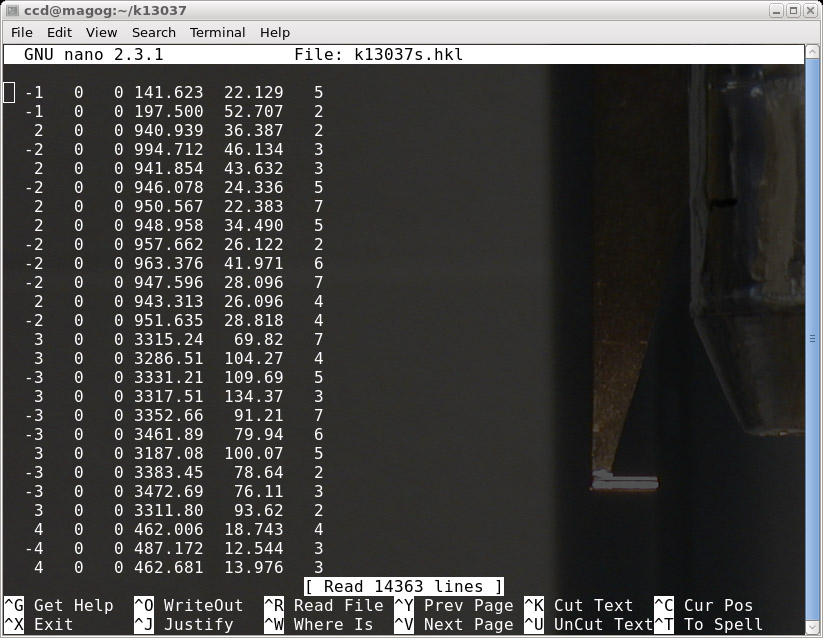
The above window shows the 'slow' '.hkl' file opened in a text editor. The cursor is
poised to remove the (-1 0 0) entries. Go ahead and cut out these and the other
"disagreeables" from the 'slow' scan '.hkl' file, and save the result. (For the sake of
good book-keeping it is wise to keep a copy of the unedited 'slow' files, but if they
are ever needed they can easily be reproduced from the frames). Disk space
is so cheap nowadays that there is never any reason to erase data!
We now have the files ('fast' and edited 'slow' '.hkl') ready for merging in XPREP. Go on to the last part of this tutorial (part 6).
We now have the files ('fast' and edited 'slow' '.hkl') ready for merging in XPREP. Go on to the last part of this tutorial (part 6).
1) Extract the intensity data from the diffraction frames.
2) Run a first pass through with Scalepack.
3) Create '.sad' input files for SADABS.
4) Run SADABS separately for fast and slow scans.
5) Identify overload intensities and edit slow .hkl file.
6) Merge fast and slow scans in XPREP.
2) Run a first pass through with Scalepack.
3) Create '.sad' input files for SADABS.
4) Run SADABS separately for fast and slow scans.
5) Identify overload intensities and edit slow .hkl file.
6) Merge fast and slow scans in XPREP.